리눅스 - 디스크 정보, TAR, GZIP, AWK
디스크 사용
명령어 df : 전체 파일 시스템의 정보를 보여준다. 보여주는 속성은 Filesystem(시스템 명), 1K-blocks(용량), Used(사용량), Available(남은 용량), Use%(사용률), Mounted on(마운트 된 디렉토리)이다. 여기서 마운트란, 디렉토리와 실제 파일 시스템(디스크)을 연결시키는 걸 의미한다.

udev라는 이름의 파일 시스템은 입출력 장치 처리를 담당하는 /dev 디렉토리에 연결되어 있고, 946,764KB의 저장공간을 가지며, 그 중 하나도 사용하지 않았다.
df가 디스크의 정보를 알려주는 반면, 파일이나 디렉토리의 디스크 사용량을 알려주는 명령어도 있다. du 명령어이다.
du [-s] 파일명들 : 파일이나 디렉토리가 사용하는 디스크 블록 수(한 블록에 0.5KB) 를 각각 알려준다. 파일명을 입력하지 않으면 현재 디렉토리 내의 모든 파일에 대해 알려준다.
>> -s 옵션 : 각각 알려주는 대신 전체 총합만 알려준다.
묶기와 압축
과제 제출을 위해 알집으로 파일들을 압축한 경험이 있을 것이다. 리눅스에서는 알집같은 민간프로그램 대신 압축을 위한 유틸리티를 제공한다. 그러나 만약 압축할 파일이 여러 개라면, 압축을 위해 먼저 여러 파일들을 하나로 직접 묶어야 한다. 알집에서는 신경쓸 필요가 없었지만 리눅스에서는 다르다. 묶은 파일, 그리고 이를 담당하는 유틸리티를 tar(tape archive)라고 부른다. 묶음 저장소? 라고 생각하면 될 듯.
tar 명령어를 이용해 유틸리티를 사용할 수 있으며, 용법은 다음과 같다.
>> tar -cvf 타르파일명 파일명들 : create, v와 f는 기본적으로 붙는다고 생각하고 신경쓰지 말자. 여러 파일을 묶어 타르파일명.tar 파일을 생성한다.
>> tar -xvf 타르파일명 : extract, 묶인 타르파일을 풀어 원래 파일들을 복원한다.
>> tar -tvf 타르파일명 : table of content, 타르파일의 내용만 확인할 수 있다.
실습을 위해 홈 디렉토리 아래의 모든 파일을 타르파일로 묶은 후, 하위 디렉토리로 이동시켜 내용을 확인하고 묶기를 풀어보았다.


모든 파일을 tar 명령어로 묶어 all.tar 파일이 생성됐다.
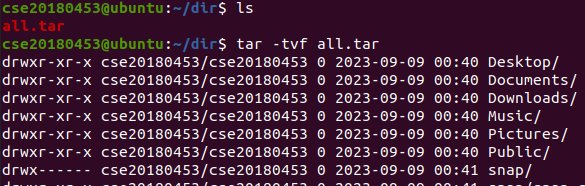
-t 옵션을 사용하면 ls -l처럼 접근권한이나 소유자, 크기 등 상세 정보를 확인할 수 있다.
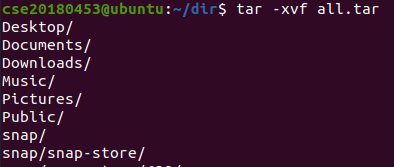
-x 옵션을 사용해 묶기를 해제하자 모든 파일이 pwd에 복원되었다.
파일들을 한데 묶어 타르파일을 생성했으니 이제 압축을 해볼 차례다. 압축 명령어는 알집과 비슷한 gzip이다.
gzip 타르파일명 : 묶어둔 파일을 작게 압축한다. 압축시 .gz 파일이 생성된다. -l 옵션으로 압축파일 내부 파일의 정보를 확인할 수 있다.
압축 과정이 묶기 -> 압축이였으니, 압축 해제 과정은 역순인 압축 해제 -> 풀기로 진행된다.
압축 해제는 gzip 명령어 옵션으로 -d (decompress)를 입력하면 된다. gzip -d .gz 파일 명령어 입력 시 타르파일이 뿅 나타난다. 다시 위에서 배운 tar -xvf 명령어를 이용해 묶은 타르파일을 풀어헤쳐 전체 파일을 복원할 수 있다.
AWK
'텍스트 줄 처리기'라고 생각하면 된다. 이름이 awk인 이유는 개발자 3명 이름의 첫 글자를 합쳤기 때문이다... 쩝
>> awk 프로그램 파일명 : 텍스트의 각 줄마다, 줄이 조건을 만족할 경우 필드(단어)에 대해 지정한 처리를 수행한다. 이 조건과 액션(처리)이 하나의 명령어를 구성하고, 명령어들이 모여 하나의 awk 프로그램을 구성한다.
>> -f 프로그램파일 : 프로그램이 복잡할 경우 awk -f 옵션을 사용해 미리 작성한 awk 프로그램 파일을 적용할 수 있다. 옵션을 적용하지 않으면 터미널을 이용해 직접 작성하면 된다.
awk 문법
0. 형식
터미널 입력과 파일 입력에서 명령어는 조건 { 액션 } 의 공통된 형식을 갖는다. 대신 직접 작성할 때는 명령어 전체를 작은따옴표로 감싸줘야 하고, 명령어가 여러 줄일 경우 세미콜론 ;으로 구분해야한다. 파일에 작성할 때는 각 명령어를 줄바꿈으로 구분한다.
1. 변수
변수는 일반 변수와 내장 변수로 나뉜다. 일반 변수는 여타 프로그래밍 언어와 다르게 별도의 선언이 필요 없고 사용 시 값이 0인 정수형 변수로 초기화된다. 내장 변수는 awk 프로그램 내에서 이미 특정한 값을 나타내는 변수들로 대표적인 내장 변수들은 다음과 같다.
>> $n : 입력받은(현재) 줄의 n번째 필드(단어), 번호는 1부터 시작하며 $0은 줄 전체를 의미한다.
>> NF : number of field, 현재 줄의 필드 개수
>> NR : number of row, 현재 줄의 줄 번호
>> FS : field separator, 필드 구분자로 기본값은 공백 문자. FS="사용할 문자" 꼴로 사용한다.
>> ARGC, ARGV : argument count/vector : 명령줄 인수의 개수, 명령줄 인수의 배열 (파일명 접근에 주로 사용)
2. 조건
형식에서 볼 수 있듯 액션을 명시한 { } 앞에 붙어, 해당 조건을 만족하는 줄에 대해 액션을 수행한다. 조건으로는 연산자나 정규식 패턴, 또는 키워드를 사용할 수 있다.
>> 키워드 : BEGIN (파일 시작), END (파일 끝). 말 그대로 파일 시작, 파일 끝에서만 지정한 액션을 수행한다.
>> 패턴 : /RegEx/. 슬래시/로 찾고자 하는 정규식 패턴의 양 끝을 감싼 형태. 해당 패턴이 존재하는 줄에 대해 지정한 액션을 수행한다.
>> 연산자 : C 언어에서 사용하는 관계, 논리 연산자와 동일하다. 예를 들어 'NR % 2 == 0 && NR <= 10 { 액션 }'이라는 명령어에서 조건은 10 이하의 짝수번째 줄에 대해서만 액션을 실행한다.
3. 액션
조건과 마찬가지로 C언어와 비슷한 문법을 사용할 수 있다. if나 for, while 같은 조건/반복문, x += 5 등의 연산 및 할당문, print, printf " " 등의 출력문을 사용 가능하다. 아울러 변수 부분에서 나온, 필드 참조를 위한 $연산자도 동일하게 사용할 수 있다.
4. 예시
문법 이해를 돕기 위한 몇 가지 예시를 가져왔다. 텍스트 파일 you.txt에는 8줄의 노래 가사가 저장되어있다.
4-1) 처리 전 'program start'를 출력하고 각 문장마다 내용과 필드 수를 출력한다.
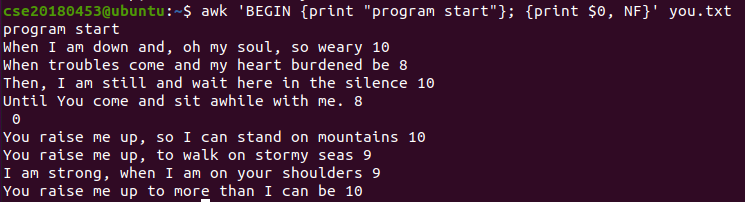
파일로 작성하면 다음과 같다. 따옴표를 쓰지 않으며 각 명령어를 줄바꿈으로 구분한다.
-----program.awk-----
BEGIN {print "program start"} //조건 : 파일 시작, 액션 : 문자열 출력
{print $0, NF} //조건 : 항상, 액션 : 줄 전체와 필드 수 출력
-----shell--------
awk -f program.awk you.txt4-2) When으로 시작하는 문장에 대해 홀수번째 필드만 출력하고, 그러한 문장의 개수를 변수에 저장해 출력한다.
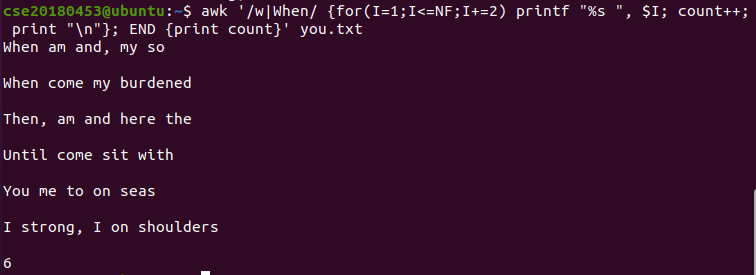
파일로 작성하면 다음과 같다.
-----program.awk-----
/w|When/ //조건 : 정규식, when 또는 When
{
for(i=1;i<=NF;i+=2) //액션 : 반복문, 1번부터 맨 끝(NF번) 필드까지 홀수번째만 출력
printf "%s ", $i; //print는 매번 줄바꿈이 생기므로 printf 사용해 출력형식 지정
count ++; //별도의 선언 없이 변수 사용
print "\n";
}
END {print count} //조건 : 파일 맨 끝, 액션 : 변수 값 출력4-3) 단어 별 출현 빈도수를 계산. 쉘에서 지원하는 연관 배열을 사용한다. 연관 배열은 일종의 해쉬맵으로, 문자열을 인덱스로 사용할 수 있다. 배열 역시 일종의 변수이므로 선언할 필요 없이 사용하면 된다.
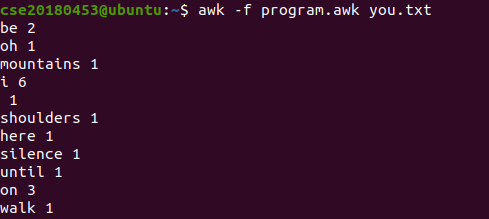
awk 프로그램

BEGIN에서, 구분자를 알파벳을 제외한 모든 문자로 정의한다.
모든 줄에서, for를 이용해 모든 필드에 대해 연관 배열 words에서 해당 필드를 키로 하는 원소의 값을 1 증가시킨다.
tolower 함수는 문자열 내 모든 문자를 소문자로 변환한 문자열을 반환한다.
awk에는 문자열 처리(length, gsub), 입출력(print), 수학 함수(sqrt, rand) 등 다양한 내장 함수가 있으므로 여기에 모두 정리하는 것은 무리가 있으며 필요할 경우 공식 문서를 찾는 것을 권장한다.
END에서, 범위 기반 for문을 이용해 words의 모든 배열의 키와 값을 출력한다.
실행 결과